DeepSeek OCR 开发调试环境¶
概述¶
本文档介绍如何使用 DevPod 快速搭建 DeepSeek OCR 的开发调试环境,帮助开发者在三分钟内完成环境配置并开始模型推理测试。
先决条件¶
在开始之前,请确保您已完成以下准备工作:
- 拥有一个阿里云账号
- 登录 FunModel 控制台
根据控制台的指引,完成 RAM 相关的角色授权等配置;如果您当前使用的是旧版控制台页面,请点击右上角的“新版控制台”按钮,切换至新版界面后再进行操作。
创建 DeepSeek OCR DevPod¶
- 点击 自定义开发。
-
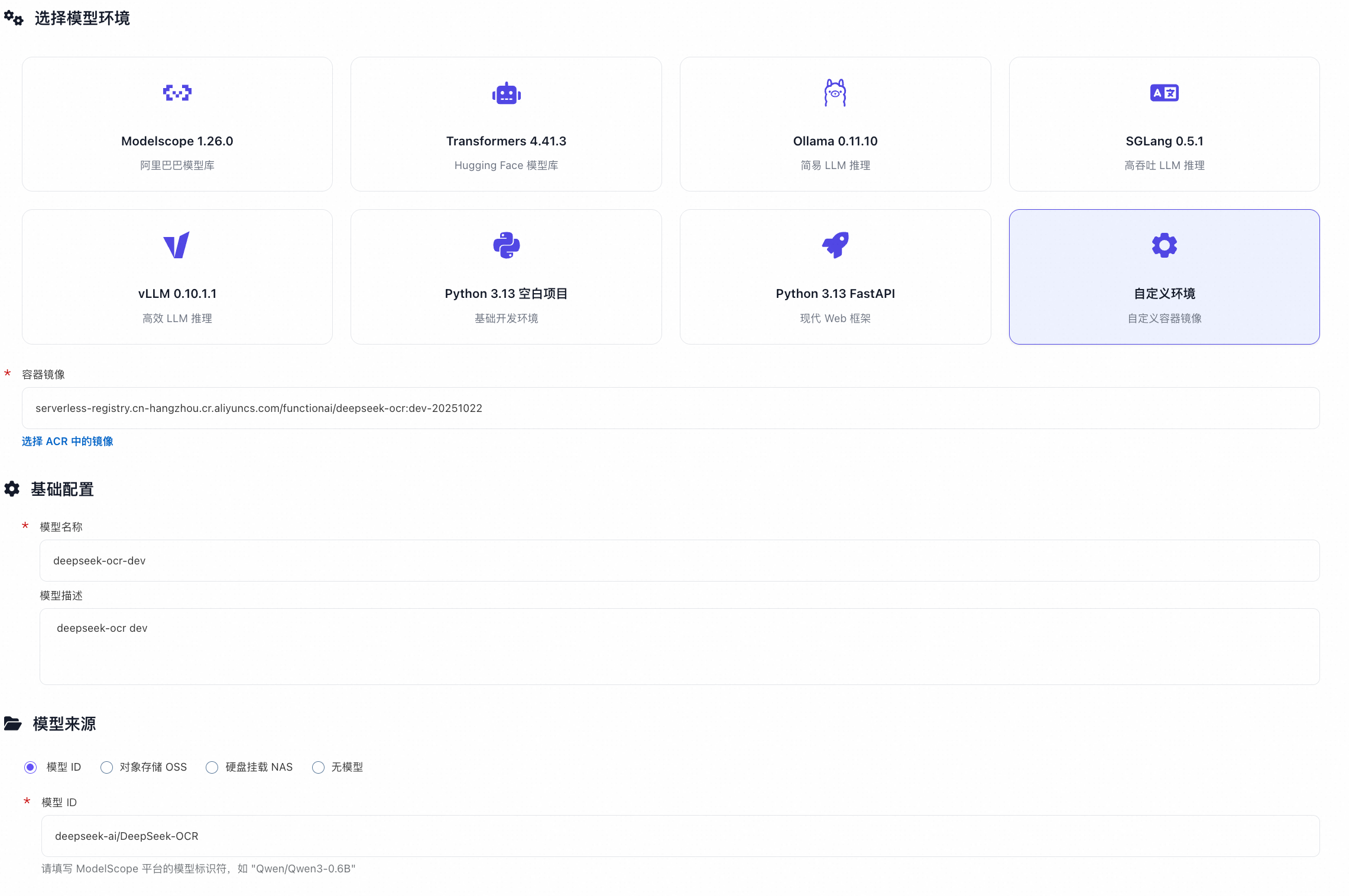
选择 自定义环境,并按如下配置:
-
镜像地址
-
中国大陆地区:
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:deepseek-ocr-v1 -
海外全球地区:
serverless-registry.ap-southeast-1.cr.aliyuncs.com/functionai/devpod-presets:deepseek-ocr-v1
-
-
模型名称:输入一个名称,例如
deepseek-ocr-dev - 模型来源:填写
deepseek-ai/DeepSeek-OCR - 启动命令:保持默认,无需修改
- 实例规格:选择
GPU性能型 - 点击 DevPod开发调试 按钮(注意:不要点击"创建模型服务")

-
-
等待部署成功(通常 1–2 分钟)。
配置和测试¶
DevPod 启动后,模型已自动下载至 NAS 挂载路径 /mnt/{模型名称}(例如 /mnt/deepseek-ocr-dev)。您可在 Web IDE 中上传测试图片,并运行示例脚本进行推理。
HuggingFace Transformers 示例¶
- 打开终端,进入 HF 示例目录:
- (可选)上传自己的测试图片,替换
input/test.png。 - 执行推理:
-
查看结果:
- 终端会直接打印识别文本
- 结果文件保存在
output/目录下

vLLM 示例¶
vLLM 支持图像、PDF 和批量图像处理。
单图推理¶
# /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
INPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/input_image/test.png'
OUTPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/output_run_dpsk_ocr_image'
执行:
PDF 推理¶
# /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
INPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/input_pdf/test.pdf'
OUTPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/output_run_dpsk_ocr_pdf'
执行:
批量图像处理¶
# /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
INPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/input_image/'
OUTPUT_PATH = '/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/output_run_dpsk_ocr_eval_batch/'
执行:
提示:所有输入路径下的图片文件将被自动处理,结果统一输出到
OUTPUT_PATH。
启动和停止 DevPod¶
DevPod 运行中会产生费用,尤其是使用 GPU 实例时费用较高。为了节省成本,当暂时不使用 DevPod 时,建议点击"关闭开发环境"按钮停止实例;需要继续使用时,点击"启用开发环境"按钮即可启动。DevPod 的启停操作通常在 1 分钟内完成。