自定义模型部署¶
概述¶
自定义模型部署功能允许用户部署自己的模型或使用预训练模型,支持多种部署方式以满足不同的业务需求。本文档详细介绍如何使用 vLLM、SGLang 和自定义镜像等方式部署模型。
您可以根据如下图参考,开启您的自定义部署或者 DevPod 开发流程

先决条件¶
在开始之前,请确保您已完成以下准备工作:
- 拥有一个阿里云账号
- 登录 FunModel 控制台
根据控制台的指引,完成 RAM 相关的角色授权等配置;如果您默认是老版页面,请点击右上角新版本控制台切换到新版
- 点击 自定义开发
vLLM 部署¶
vLLM 是一个快速且易于使用的 LLM 推理库,支持多种模型架构。
注意: vLLM 仅针对大语言模型 (LLM)
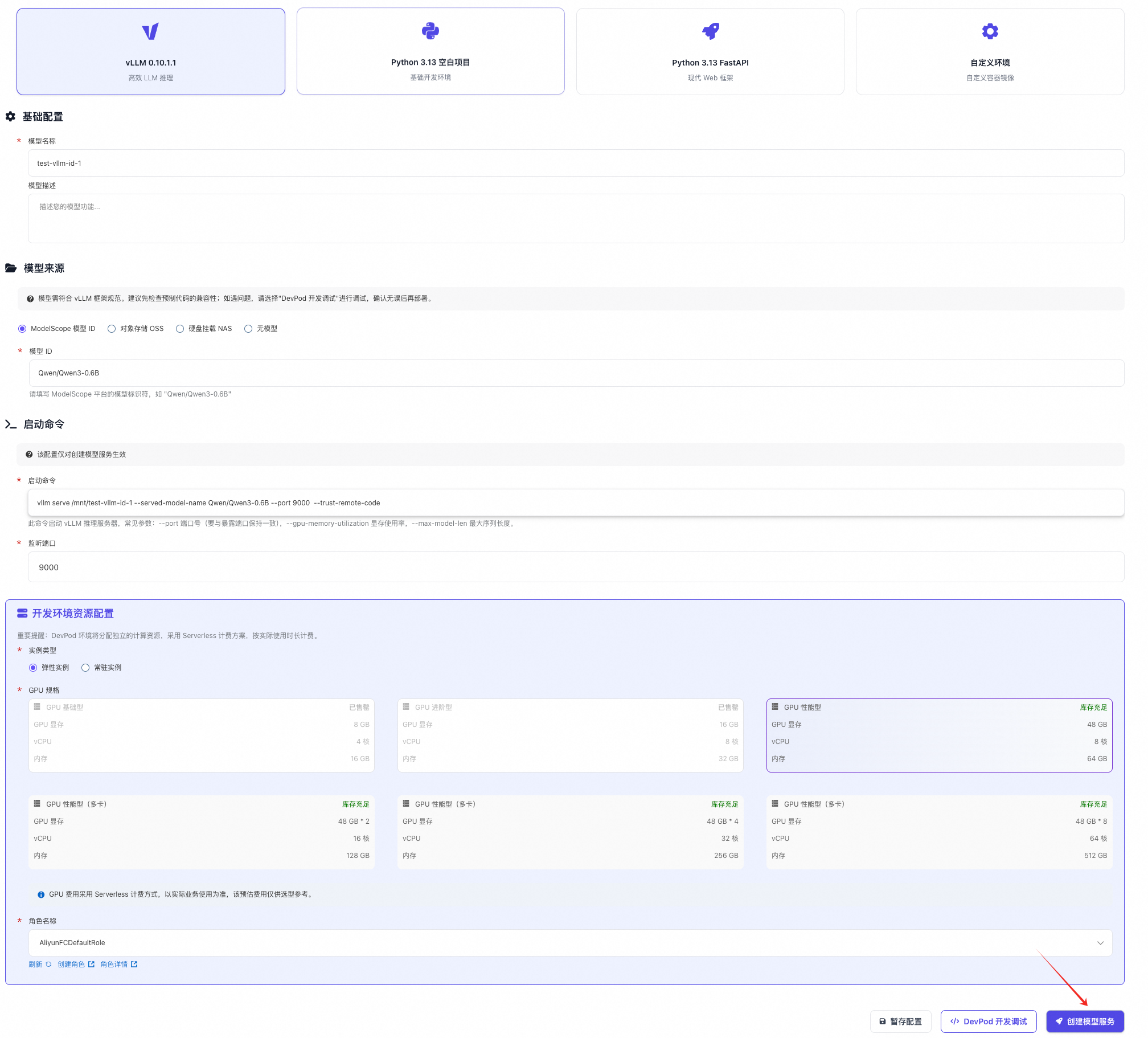
模型来源: ModelScope 模型 ID¶
- 选择 vllm 镜像
- 填写模型名称,按照自己的需求取一个有意义的名字
- 填写模型描述(可选)
- 模型来源选中 "ModelScope 模型 ID",填写您想要部署的模型ID,比如
Qwen/Qwen3-0.6B - 注意一定要填写 ModelScope 上真实存在的模型 ID
- 选择弹性实例或者常驻资源池实例
- 默认的启动命令和端口绝大部分的时候都是正确的,比如: 一般不需要您这边做修改,除非您需要加一些额外的 vLLM serve 启动参数
- 点击 创建模型服务 按钮,等待模型下载以及模型服务启动成功
模型来源: 对象存储 OSS¶
- 选择 vllm 镜像
- 填写模型名称,按照自己的需求取一个有意义的名字
- 填写模型描述(可选)
- 模型来源选中 "对象存储",填写你提前在 OSS 上准备的模型
- 选择弹性实例或者常驻资源池实例
- 默认的启动命令和端口绝大部分的时候都是正确的(仅需要修改 served-model-name 参数值),比如:
其他要加一些额外参数可以参考 vLLM serve 启动参数
vllm serve /mnt/fun-model-test/Qwen/Qwen3-0.6B --served-model-name Qwen/Qwen3-0.6B --port 9000 --trust-remote-code - 点击 创建模型服务 按钮,等待模型服务启动成功

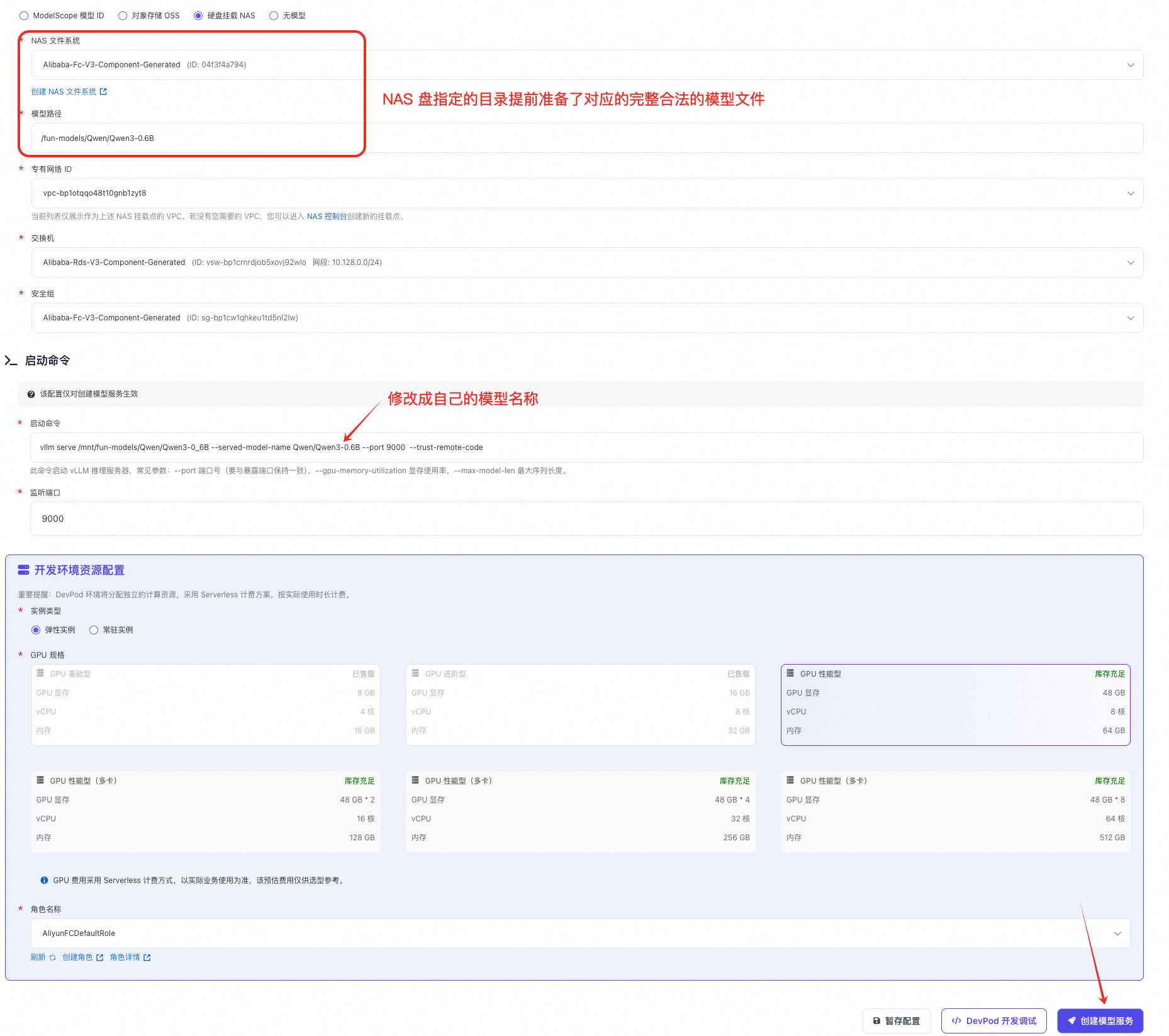
模型来源: 硬盘挂载 NAS¶
- 选择 vllm 镜像
- 填写模型名称,按照自己的需求取一个有意义的名字
- 填写模型描述(可选)
- 模型来源选中 "硬盘挂载 NAS",填写你提前在 NAS 上准备的模型路径
- 选择弹性实例或者常驻资源池实例
- 默认的启动命令和端口绝大部分的时候都是正确的(仅需要修改 served-model-name 参数值),比如:
其他要加一些额外参数可以参考 vLLM serve 启动参数
vllm serve /mnt/fun-models/Qwen/Qwen3-0_6B --served-model-name Qwen/Qwen3-0.6B --port 9000 --trust-remote-code - 点击 创建模型服务 按钮,等待模型服务启动成功
SGLang 部署¶
SGLang 是一个专为大型语言模型设计的快速推理框架。
注意: SGLang 仅针对大语言模型 (LLM)
模型来源: ModelScope 模型 ID¶
- 选择 sglang 镜像
- 填写模型名称,按照自己的需求取一个有意义的名字
- 填写模型描述(可选)
- 模型来源选中 "ModelScope 模型 ID",填写您想要部署的模型ID,比如
Qwen/Qwen3-0.6B - 注意一定要填写 ModelScope 上真实存在的模型 ID
- 选择弹性实例或者常驻资源池实例
- 默认的启动命令和端口绝大部分的时候都是正确的,比如: 一般不需要您这边做修改,除非您需要加一些额外的 SGLang server_arguments
- 点击 创建模型服务 按钮,等待模型下载以及模型服务启动成功
模型来源: 对象存储 OSS¶
- 选择 sglang 镜像
- 填写模型名称,按照自己的需求取一个有意义的名字
- 填写模型描述(可选)
- 模型来源选中 "对象存储",填写你提前在 OSS 上准备的模型
- 选择弹性实例或者常驻资源池实例
- 默认的启动命令和端口绝大部分的时候都是正确的,比如:
其他要加一些额外参数可以参考 SGLang server_arguments
python3 -m sglang.launch_server --model-path /mnt/fun-model-test/Qwen/Qwen3-0.6B --host 0.0.0.0 --port 9000 - 点击 创建模型服务 按钮,等待模型服务启动成功
模型来源: 硬盘挂载 NAS¶
- 选择 sglang 镜像
- 填写模型名称,按照自己的需求取一个有意义的名字
- 填写模型描述(可选)
- 模型来源选中 "硬盘挂载 NAS",填写你提前在 NAS 上准备的模型路径
- 选择弹性实例或者常驻资源池实例
- 默认的启动命令和端口绝大部分的时候都是正确的,比如:
其他要加一些额外参数可以参考 SGLang server_arguments
python3 -m sglang.launch_server --model-path /mnt/fun-models/Qwen/Qwen3-0_6B --host 0.0.0.0 --port 9000 - 点击 创建模型服务 按钮,等待模型服务启动成功
自定义镜像¶
对于需要自定义环境的场景,可以使用自定义镜像部署模型。
适用场景¶
- 针对大语言模型,可以自己定制 vLLM 或者 SGLang 镜像
- 需要特殊依赖或配置的模型
- 能直接命令行直接运行的模型应用(镜像中已经有模型,比如 PaddleOCR-VL 离线版镜像 serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/paddlex-genai-vllm-server:20251111-offline)
官方预置镜像¶
DevPod 提供了一系列预置镜像,用于快速启动自定义部署环境。如果您使用全球 Region,将镜像中的 cn-hangzhou 替换成 ap-southeast-1 即可。
| 镜像名称 | 说明 |
|---|---|
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/vllm-openai:v0.11.0 |
vllm |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:debian-13-v1 |
Debian 13 基础镜像 |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:deepseek-ocr-v1 |
DeepSeek OCR 镜像 |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:golang-1.25-v3 |
Golang 1.25 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:golang-1.25-gin-v3 |
Golang 1.25 + Gin 框架 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:node-24.6.0-v2 |
Node.js 24.6.0 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:node-24.6.0-express-v2 |
Node.js 24.6.0 + Express 框架 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:ollama-0.11.10-v1 |
Ollama 0.11.10 |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:python-3.11-v2 |
Python 3.11 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:python-3.11-modelscope-1.26.0-cuda-12.1-torch-2.3.1-tf-2.16.1-ubuntu-22.04-v3 |
Python 3.11 + ModelScope + CUDA 12.1 + PyTorch 2.3.1 + TensorFlow 2.16.1 (Ubuntu 22.04 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:python-3.12-v1 |
Python 3.12 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:python-3.12-pytorch-v1 |
Python 3.12 + PyTorch (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:python-3.13-v5 |
Python 3.13 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:python-3.13-fastapi-v3 |
Python 3.13 + FastAPI 框架 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:python-3.13-flask-v2 |
Python 3.13 + Flask 框架 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:python-3.13-slim-v3 |
Python 3.13 轻量版 (Debian 环境) |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:sglang-0.5.1-v2 |
SGLang 0.5.1 |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:transformers-4.41.3-v1 |
Transformers 4.41.3 |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:ubuntu-24.04-v1 |
Ubuntu 24.04 基础镜像 |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:vllm-0.10.1.1-v2 |
vLLM 0.10.1.1 |
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:wan2.2-v1 |
WAN 2.2 镜像 |
自定义 vllm 镜像启动自己微调的 Qwen/Qwen3-0.6B 模型示例¶
准备工作:
在期望的 region 中存在一个 OSS Bucket, 并且模型已经上传上去
- 选择自定义环境, 输入镜像
serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/vllm-openai:v0.11.0如果是 functionai 选择全球区域, 输入镜像为
serverless-registry.ap-southeast-1.cr.aliyuncs.com/functionai/vllm-openai:v0.11.0 - 选择模型来源为对象存储 OSS, 填写你提前在 OSS 上准备的模型
- 选择弹性实例或者常驻资源池实例
- 填写启动命令如下:
vllm serve /mnt/fun-model-test/Qwen/Qwen3-0.6B --served-model-name Qwen/Qwen3-0.6B --port 9000 --trust-remote-code
/mnt/fun-model-test/Qwen/Qwen3-0.6B,表示 bucket 名字为 fun-model-test-hz,模型位于 OSS 的 objectKey 为 Qwen/Qwen3-0.6B, --served-model-name 为推理服务 model 参数名字, 一般和 model_id 对齐; 其他要加一些额外参数可以参考 vLLM serve 启动参数
- 点击 创建模型服务 按钮,等待模型服务启动成功

使用 DevPod 开发自定义镜像¶
如果模型无法通过命令行直接运行,建议使用自定义镜像启动 DevPod,在其中完成模型的开发与调试,最终将调试好的环境打包为镜像以完成部署。
具体流程请参考 三分钟拥有一个 deepseek-ocr 的体验开发调试 GPU 环境
配置参数说明¶
启动命令参数¶
vLLM 常用参数¶
--served-model-name:指定服务模型名称--port:指定服务端口--trust-remote-code:信任远程代码--tensor-parallel-size:张量并行大小--max-model-len:最大模型长度
SGLang 常用参数¶
--model-path:模型路径--host:监听主机地址--port:监听端口--tp-size:张量并行大小
最佳实践¶
模型选择建议¶
- 根据业务需求选择合适的模型大小
- 考虑成本和性能的平衡
- 优先使用经过优化的预训练模型
性能优化¶
- 合理配置实例规格和数量
- 使用模型量化技术减少资源消耗
- 根据实际需求,设置合理的推理框架的启动参数优化性能
安全考虑¶
- 确保模型来源可靠
- 避免在镜像中硬编码敏感信息
- 定期更新基础镜像和依赖库
- 使用环境变量传递密钥等敏感配置
故障排除¶
部署失败¶
- 检查模型路径是否正确
- 验证模型文件是否完整
- 确认实例规格是否满足模型要求
- 查看部署日志获取详细错误信息
服务启动失败¶
- 检查启动命令参数是否正确
- 验证模型文件权限
- 确认配置的端口和启动命令端口是否一致,以及启动命令中的 host 是否为
0.0.0.0 - 查看服务日志获取详细错误信息
性能问题¶
- 检查实例资源使用情况
- 调整模型参数配置
- 考虑使用更高规格实例